Lee 2022 - RQ-VAE
Autoregressive Image Generation using Residual Quantization
Vector quantization VQ-VAE is used to represent an image as a sequence of discrete codes. After quantizing, an autoregressive model (AR model, e.g. transformer) is used to predict the codes.
This paper aims to reduce the sequence length of the discrete codes, as it becomes more computationally efficient for the AR model. However, reducing the sequence length (aka reducing the spatial resolution) causes a rate-distortion trade-off. The dilemma is such:
- Increasing the codebook size improves resolution of discretization to preserve quality
- But increasing the codebook size also increases the probability of codebook collapse, where only a subset of codes are used
The main idea of RQ-VAE is to reduce the spatial resolution by more precisely approximating the feature map at each location. Instead of increasing the codebook size, we use the codebook to recursively quantize the feature map in a coarse-to-fine manner. That is, the feature representation at each location is the sum of the selected codebook vectors at each level. For a codebook where each level has codebook vectors and levels, we can represent vectors for learning just vectors.
- The paper claims that due to this precise approximation, they can use just
8 x 8latents to represent a256 x 256image. That is a reduction of1024x!
Note: other papers usually use a distinct set of vectors for each codebook level, but in this paper they use a shared codebook for all levels. This is probably an implementation detail / hyperparameter to be tuned.
Method
There are two main stages:
- Stage 1: Residual Quantized VAE.
- Stage 2: RQ-Transformer.
Stage 1: Residual Quantized VAE
Let a codebook be a finite set be a codebook of tuples of a code k and its code embedding .
- is the codebook size
- is the code embedding dimension
Given a vector , let denote the discrete code of :
The normal VQ-VAE flow is such:
- Start with an input image , where are the original image dimensions
- The encoder extracts a feature map , where are downsampled times to form the latent feature map
- Applying the discretization independently to each position, we obtain a code map :
- We also obtain the quantized feature map :
- Finally, we decode the quantized feature map to reconstruct the image:
For Residual Quantization, we instead represent as an ordered tuple of codes:
Where is the discrete latent code of at depth . Specifically, we obtain by recursively quantizing the residual. Starting with residual , we compute the next as follows:
Finally, we represent as the quantized embedding of using the sum of embedding across all depths.
Note: by using a shared codebook and summing up the embeddings at each depth, this resembles bloom hashing (see Weinberger 2009). The difference is that we recursively / sequentially encode the residuals, whereas bloom hashing simultaneously applies multiple independent hashes and sums up those embeddings at the hashed positions.
However, as the experiments indicate, the embedding norms get smaller as we go deeper into the codebook levels, since it learns a coarse-to-fine encoding. So it seems to make better sense to have separate codebook vectors for each level.
The RQ-VAE flow is thus identical to the VQ-VAE flow above, except that the discretization step differs:
- Start with an input image
- Encoder extracts
- Discretize each position to get code map (note the additional dimension , since we now have codes per position):
- Finally decode:
RQ-VAE Training
The loss is:
The first loss is the reconstruction error of making the RQ-VAE roundtrip. The second loss is the commitment loss, which aims to push the encoder to reduce the quantization errors.
- Note that the commitment loss sums up the quantization error at each level of the codebook, not just the final quantization error at the end
- Also note that the authors did not include the loss to update the codebook as in VQ-VAE; instead they use the Exponential Moving Average approach to update the codebook using the average encoder output assigned to each cluster
Stage 2: RQ-Transformer
Given that we have learned a code map of , the goal is to now autoregressively predict the code map (laid out in raster scan order). Specifically, let us lay out into a 2D array of codes , where . Thus each row of (call it ) will contain codes:
Note that is laid out in raster scan order, meaning that we read the first row of pixels left-to-right, then move to the next row and so on.
Thus the goal of stage 2 is to learn an autoregressive model which learns the joint probability function , given all the prior tokens (i.e. causal masking). Note that we predict codes for each position before moving on to the next:
The natural approach is to just fit an autoregressive transformer decoder to this unrolled sequence (of length , where ). This incurs attention bottleneck complexity of . However, this paper argues that this is inefficient as it does not exploit the structure of our tokens, and proposes a customized RQ-transformer for this situation.
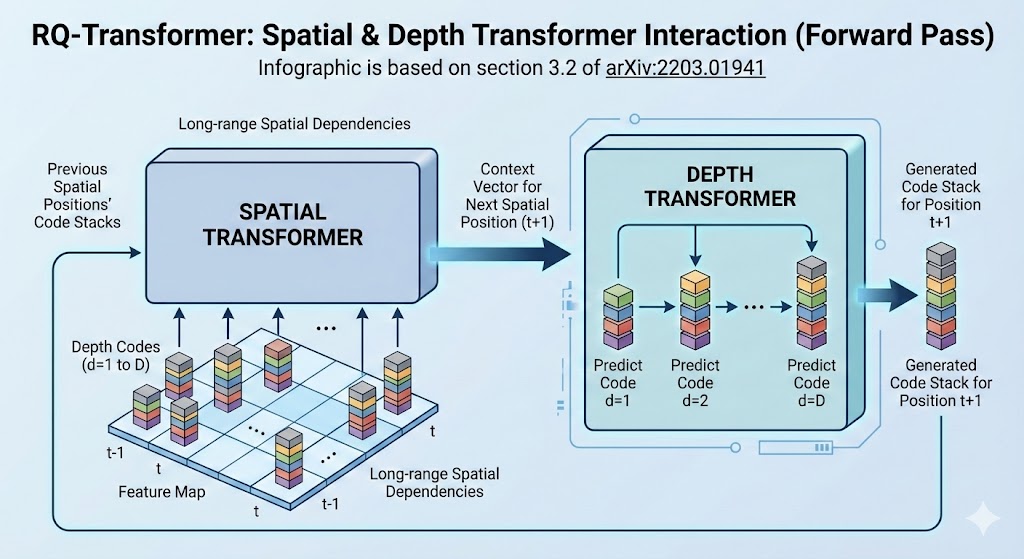
The idea is that there are two orthogonal dimensions, so we can decouple and create a specialized transformer to handle each one orthogonally:
- The first two dimensions, and , encode the position
- The last dimension, , encodes the depth
 |
| RQ-Transformer Architecture |
Spatial Transformer
The spatial transformer encodes the position dimension and marginalizes away the depth dimension. It is concerned with the "big picture". Specifically, each input position to the spatial transformer is:
Note that:
- is the position encoding for spatial position
- We re-use the quantized embedding codebook vectors to represent inputs to the spatial transformer
- The depth position is marginalized out, such that we only need to encode positions with the spatial transformer
- is a special case for start of sequence and will have its own learnable embedding
The sequence of inputs is passed into a causally masked transformer to produce spatial context vectors like so:
Depth Transformer
Given the context vector provided by the spatial transformer, the depth transformer predicts a very short sequence of codes for this position . Thus, the depth transformer can be a smaller stack of transformer layers.
- Note: in the experiments, generally and in number of layers
Specifically, at spatial position and depth , input to the depth transformer is the sum of codebook embeddings up to depth :
The short sequence of inputs is passed into a causally masked transformer + classifier head to predict the codes for each position. The same depth transformer is reused across all spatial positions .
The autoregressive loss is simply the negative log likelihood of the correct latent token sequence:
Computation Savings
As observed above, fitting a naive transformer to the full sequence of length will incur attention complexity of . Compare this to the RQ-transformer:
- Spatial transformer: , since we marginalize away the depth dimension
- Depth transformer: , since we re-use the depth transformer times
- RQ transformer:
With , we have around 15x lower computational complexity:
- Naive approach:
4,194,304 - RQ transformer:
270,336 - Ratio:
~15x!
Other Tricks
There are two other tricks that they use in this paper, presumably to improve performance. The aim is to reduce the impact of exposure bias, which is the divergence between the samples during training and inference. During training, due to teacher forcing, we still get correct tokens to predict from at each position. During inference, since we generate each position autoregressively, errors can compound and lead the model to predict from a sequence that deviates far from what it has seen during training.
The main idea is to introduce some uncertainty into both the labels and inputs to the training process. Let us define a categorical distribution on conditioned by the encoder embedding , with probability distribution:
Thus the probability of a discrete token increases exponentially as its quantized embedding gets closer to the encoder embedding . Note that as approaches , gets sharper and converges to the one-hot distribution .
This soft approximation of the argmin is used for soft labelling of the objective when training the RQ-transformer. Specifically, note that at position and depth , we quantize by doing a nearest neighbour search for the residual vector . Hence the hard target for the RQ-transformer training is the one-hot label . Instead we replace with .
We also do Stochastic Sampling of the latent codes when generating training samples for the RQ-transformer. Instead of deterministic code selection when encoding the raw images to latent codes, we sample from the categorical distribution of .
The ablation studies show that using soft labelling + stochastic sampling significantly improves performance.
Results and Hyperparameters
General hyperparameters:
- Codebook size:
- Codebook levels:
- Latent dimension size:
- Temperature:
Generally RQ-VAE matches or outperforms image generation of other autoregressive competitors like VQ-GAN. It is also a lot faster in generation speed and memory usage.