Kaiser 2018 - Fast Decoding in Latent Space
Fast Decoding in Sequence Models using Discrete Latent Variables
This paper uses the idea in VQ-VAE to do fast decoding in latent space.
Main Idea
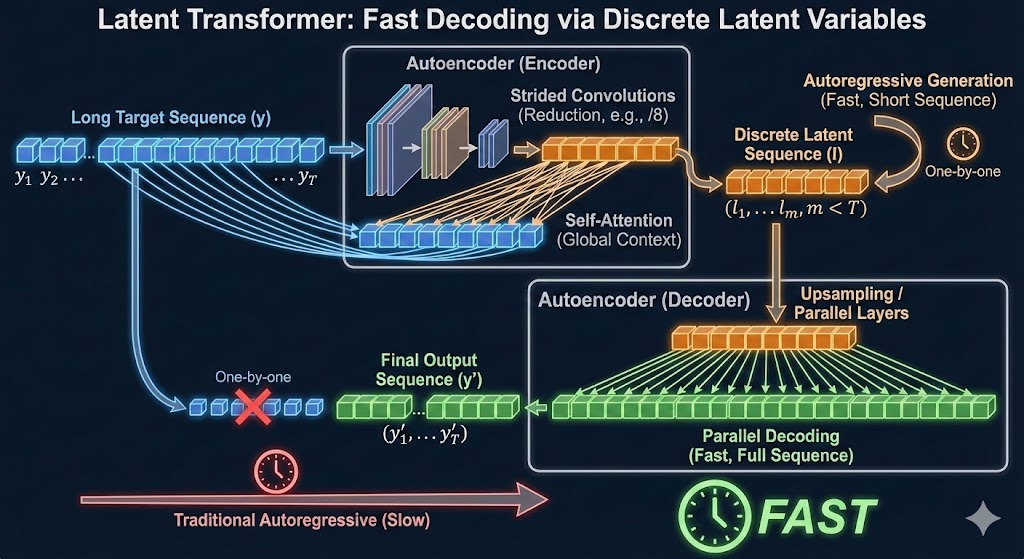
Transformers parallelize during training well, but are slow at inference due to autoregressive nature. This paper proposes to autoregressively generate in discrete latent space instead, which can be much faster depending on the compression:
- First auto-encode target sequence into discrete latent space which is a shorter sequence
- Train a decoder to generate in discrete latent space autoregressively
- Decode output sequence from the shorter latent sequence in parallel
Here is an infographic from nano banana that captures the idea of generation in latent space:
 |
| Fast Generation in Latent Space |
Setup
When generating sequential output, autoregressive models generates in a canonical order. This is because the model is trained to predict:
During training, because ground truth is known, we can train in parallel. During decoding, this is a fundamental limitation.
The proposal is to first encode the original sequence into a shorter sequence of discrete tokens , where is much smaller than . This latent sequence is also autoregressively predicted, and subsequently decoded in parallel back into the original token space. In the experiments, .
Latent Transformer
The latent transformer is described in terms of a machine translation task. Given an input sequence in English, and a corresponding output sequence in German, our input-output pair is .
The high level architecture is:
- The function will autoencode into a shorter sequence of discrete latent tokens using some discretization technique
- The latent prediction model which is a transformer will autoregressively predict based on
- The decoder is a parallel model that will decode from and the input sequence
Loss
The reconstruction loss compares the encoded - decoded output to the original target sequence :
The latent prediction loss compares the true latents generated by the autoencoder to the generated latents :
The final loss is the sum of the two:
Autoencoder
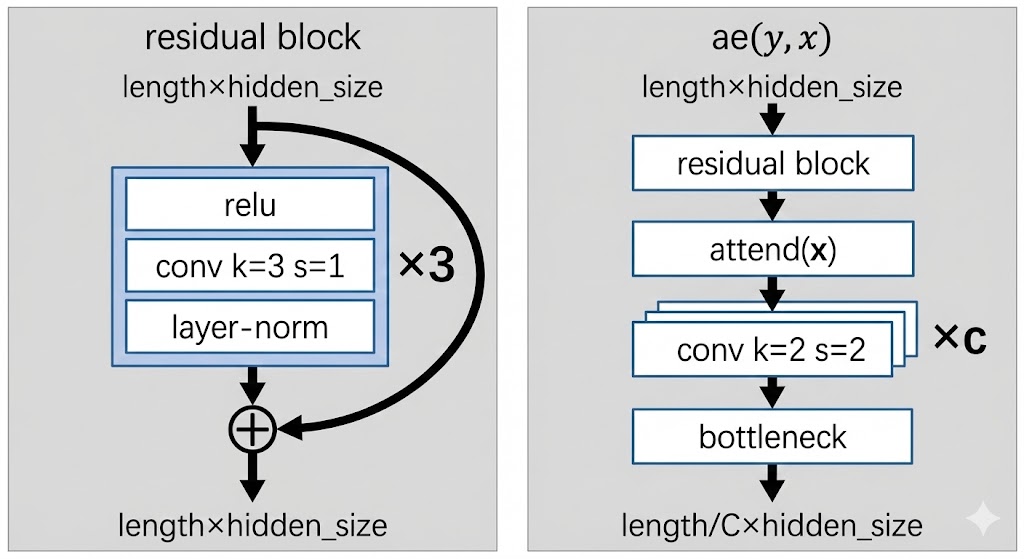
Now we describe each part in more detail. The diagram below summarizes the architecture of the autoencoder .
 |
| Autoencoder architecture |
The input to the autoencoder is of shape length x hidden_size. The aim is to shorten the sequence length by downsampling using convolutions.
We first pass through a residual block which aims to learn local features using convolutions:
- Pass through
relu - Pass through 1D convolution with
k=3, s=1. This means we look over a window of3tokens each time, and take a step of1token each step.- Since stride is
1, the sequence length is unchanged
- Since stride is
- Pass through layer norm + add the residual connection
Then we pass through a standard self attention block.
Then we pass c times through a downsampling convolution:
k=2means that we look over a window of2tokenss=2means that we stride over2steps at a time: this effectively halves the sequene length- Doing this
ctimes means we get reduction in length
Finally we pass through the bottleneck function, which has yet to be described. But essentially the bottleneck function converts the representation of hidden_size at each position into a discrete token, and then represents it instead by the embedding of the discrete token using a lookup.
Decoder
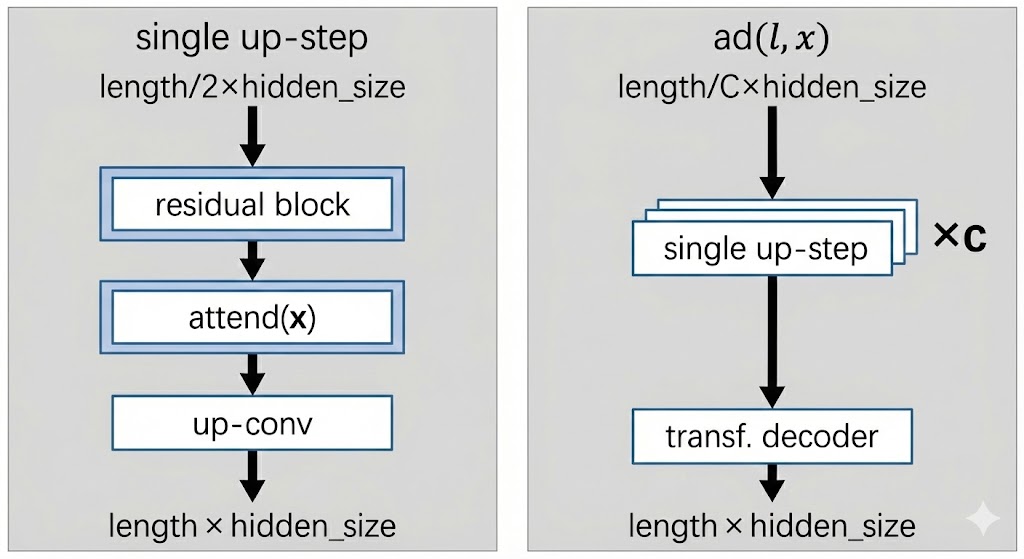
The decoder decodes from latent space back into token space.
 |
| Decoder architecture |
We first pass through c up-steps, each of which will double the sequence length of the encoded sequence:
- The same residual block from before is used
- Self attention layer is used
- An up-conv step is performed:
- A standard feed forward MLP is used that doubles the hidden dimension
- A reshape operation is done to translate the extra hidden dimension into sequence length instead
Finally, the decompressed sequence of length x hidden_size is fed into a standard transformer decoder to decode the target sequence .
- Note that for the first 10k steps of training, instead of feeding the decompressed sequence, the authors pretrain this decoder transformer model by feeding the target sequence (i.e. training it like a standard transformer decoder). This is to warm up the head so that gradients to upstream components are reasonable.
Discretization Bottleneck
This is actually the main part of the paper - how do we discretize our token sequence into latent space so that we can predict the latent tokens in an autoregressive manner?
The bottleneck function takes a target token embedding and maps it to a discrete token in :
- First, take and encode it: , where is the dimension of the latent space.
- Next, pass the encoding through a bottleneck to product a discrete latent token
- Look up embedding table using to produce an embedding to pass to the decoder
Note that the bottleneck function is applied to each sequence position in parallel, indepedently.
Gumbel Softmax
The gumbel-softmax trick is found in Jang 2016. It is a popular discretization technique.
First, we project the encoder output using a learned projection matrix , such that we get logits :
We can simply extract the discrete code for the decoder as:
For evaluation and inference, we can simply use to look up an embedding table to get . However, we cannot use this approach for training as the argmax and embedding lookup are non-differentiable.
For training, the Gumbel-softmax trick is used to make the whole thing differentiable.
- First, we draw i.i.d samples from the standard Gumbel distribution
- Then we compute the weight vector using a softmax, where for each latent dimension :
- Now we simply compute the input to the decoder as the weighted sum of the embedding table:
For low temperatures of , would be close to representing the 1-hot arg-max index of , which is what we use for evaluation and inference. Setting too high would cause divergence between training and inference, which is not ideal.
Why do we add the gumbel ? Ideally during training, we want the encoder logits to represent probabilities of a categorical distribution, from which we sample the discrete code . This ensures that we have:
- Exploration from the stochasticity
- Discretization. We also force the embedding to be a single embedding (i.e. discretization) rather than a smooshed average of several embeddings.
The gumbel-max trick tells us that choosing results in an index distributed exactly according to as dictated by the softmax of the logits, which is what we want.
Since the gumbel-max is not differentiable, we simply relax it into a softmax operation, giving us the gumbel-softmax.
Vector Quantization
The VQ-VAE is covered in VQ-VAE. Here is a brief recap.
- The encoder output is used to do nearest neighbour lookup on embedding vectors to give us:
- and
- Where
- The loss is the reconstruction loss + the commitment loss between encoder output and codebook vectors:
It turns out that the gradient update can be replaced by an exponential moving average over:
- The codebook embeddings ; and
- The count measuring the number of times is selected as a nearest neighbour
For a given mini-batch of target embeddings , we can update the exponential moving average for counts like so:
And the codebook embeddings updated as the average encoder output selected for :
is a decay parameter and set to in the experiments
Note. The paper also covers two other discretization techniques, namely improved semantic hashing and decomposed vector quantization (to counteract codebook collapse), but I don't cover it for now.
Results
The results show that the discretization bottleneck is not as good as a standard transformer, but beats all previous discrete methods and runs faster than a normal transformer.
Ablation results show that:
- Increasing the codebook size improves performance
- Increasing the ratio (i.e. shortening the sequence more aggressively) leads to speedup in inference but also clearly hurts performance
Hence it seems like there is no free lunch here.