Power Analysis
Reference: Probing into Minimum Sample Size by Mintao Wei
How to determine the minimum sample size required to achieve a certain significance level and power desired?
The following table helps us understand how type I and type II errors come into play:
| Null Hypothesis: A is True | Alternate Hypothesis: B is True | |
|---|---|---|
| Reject A | Type I Error | Good statistical power |
| Accept A | Good significance level | Type II Error |
Type I Error refers to rejecting the null hypothesis when it is actually true, e.g. when we think that an AA test has significant difference. In short, it means we were too eager to deploy a poor variant. This should happen with probability , which is the significance level which we set (typically 5%). We have a better handle on type I error because the baseline conversion rate is typically known prior to an experiment.
Type II Error refers to failing to reject the null hypothesis when the alternate is actually true, i.e. we failed to get a significant effect on an improvement that is known to be better. In short, we were too conservative and failed to deploy a winning variant. In order to reason about type II error, we need to make a guess on what is the distribution of test variant B. Typically, this is done by assuming a minimum effect we wish to detect, and setting , and re-using the standard deviation from A. With these assumptions in place, we use to determine the type II error that should only occur with probability (typically 20%). Note that since is the minimum effect we wish to detect, if the actual effect turned out to be larger, the type II error can only be smaller than our desired amount, which is ok.
Now we can derive the formula for the minimum sample size required to achieve the desired levels of type I and type II error respectively.
Let us define the baseline conversion rate as , and the minimum relative detectable effect rate as . Consequently, the minimum detectable delta is . Let the desired power level be , and the desired significance level as . Assume the scenario where we are running an AA or AB test with two variants of sample size each.
Firstly, we write down the distribution of the sample mean difference supposing we knew the true population means and standard deviations. Let and . Note that may have arbitrary distributions, e.g. they could measure proportions, revenue etc.
Under the central limit theorem, the sample means will be distributed like so with samples: , . Importantly, the difference of the sample means will have the distribution below. Note that we add the variances together because for any two independent random variables .
Now we can start working from the desired levels to the minimum sample size. We need to ensure that both objectives below are achieved with our sample size :
- Assuming null hypothesis to be true, ensure that type I error .
- Assuming alternate hypothesis to be true, ensure that type II error .
Let us define some notation first.
- Let denote the critical value under the standard normal distribution such that . This is basically the
scipy.stats.norm.ppffunction, e.g. . - We also want to denote the critical value under the distribution of the sample mean difference under the null or alternate hypothesis (these are non-standard normal distributions). Let these be and respectively.
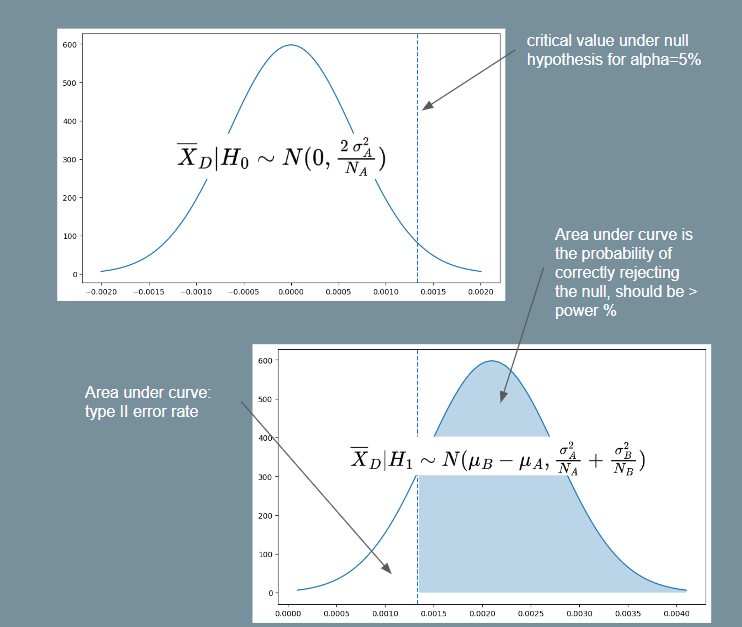 |
|---|
| Illustration for Power Analysis Derivation |
For objective 1, assuming the null hypothesis and using equation (1) above, we have . Since is a two-tailed probability and we want the critical region on the right-side, let . E.g. implies . Then:
Note that equation (2) above tells us the critical value such that we will reject the null hypothesis if the sample mean of is greater than this value. To satisfy objective 2, we must thus ensure that the probability of rejecting the null hypothesis is at least . In other words, we want . Assuming the alternate hypothesis and again using equation (1), we have . So then:
For the purpose of getting a minimum , we assume . Then using this and squaring both sides with some rearranging gives us:
Which gives us the required minimum sample size equation. If we assume , as is often assumed because we do not know the variance of the treatment, then it simplifies to the following form (as seen in Ron Kohavi's paper).
Bernoulli Events
The equation (3) above for the minimum sample size requires us to know the standard deviation under the null and alternate hypotheses. Usually, the standard deviation under the null is computed from historical data, and it is assumed that . However, if the event we are interested in may be represented as a bernoulli random variable (e.g. an impression is shown and user either clicks or does not click with some probability), the equation may be simplified.
Specifically, the variance of a bernoulli random variable with probability is . Thus, if , then , and likewise for .
So we can use and and substitute these into equation (3). We will then be able to have a minimum sample size formula by just specifying , , baseline conversion and minimum relative difference . This is the formula used by Evan Miller's sample size calculator.
Imbalanced AB Test
Another common scenario is the case where we do not split 50-50, i.e. . In this case, suppose we have , where . For example, if we have a 90-10 split, then p=9. Then we get:
Note that gives the sample size required for , and the total sample size required across both groups is .